Lexer
Tokenizer: splits raw input into a token stream for the parser.
- Author
jguillem
Enums
-
enum t_token_type
Token types for the shell’s lexer.
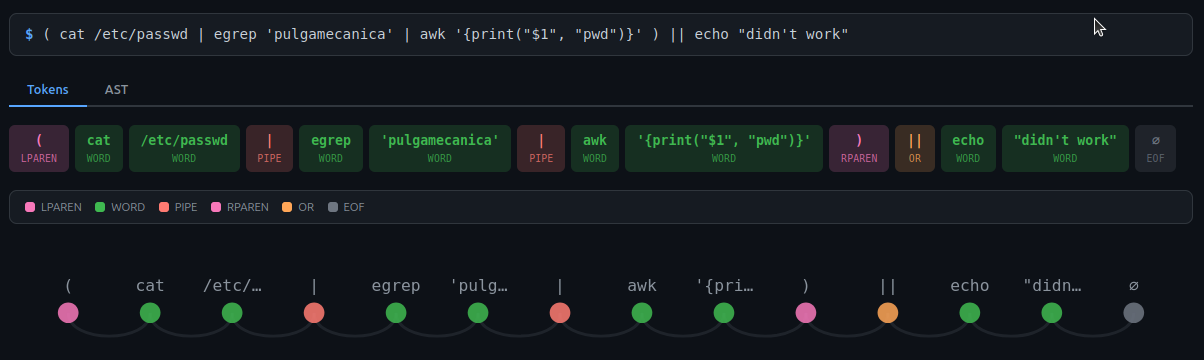
# Example $> ( cat /etc/passwd | egrep 'pulgamecanica' | awk '{print("$1", "pwd")}' ) || echo "didn't work"
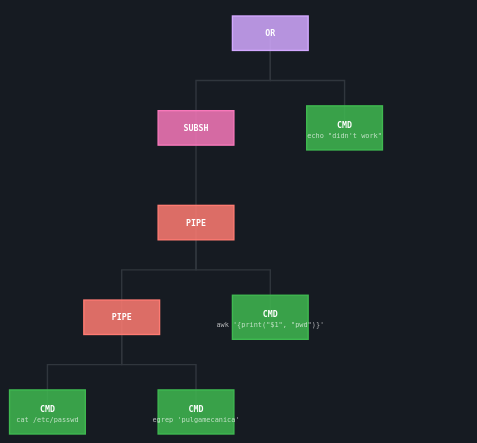
That tokenization bocomes the following AST tree:
These types represent the different kinds of tokens that can be identified in the shell’s input. They include words, operators, and special tokens like EOF and errors.
Values:
-
enumerator TOK_WORD
A word token ex: “ls” or “echo”
-
enumerator TOK_PIPE
A pipe token ex: “|”
-
enumerator TOK_AND
A logical AND token ex: “&&”
-
enumerator TOK_OR
A logical OR token ex: “||”
-
enumerator TOK_SEMICOLON
A semicolon token ex: “;”
-
enumerator TOK_AMPERSAND
An ampersand token ex: “&”
-
enumerator TOK_NEWLINE
A newline token (end of command)
-
enumerator TOK_REDIR_IN
A redirect input token ex: “<”
-
enumerator TOK_REDIR_OUT
A redirect output token ex: “>”
-
enumerator TOK_REDIR_APPEND
A redirect append token ex: “>>”
-
enumerator TOK_HEREDOC
A heredoc token ex: “<<”
-
enumerator TOK_HEREDOC_STRIP
-
enumerator TOK_REDIR_DUP_IN
A heredoc without leading tab ex : “<<-” A duplicate redirect input token ex: “<&”
-
enumerator TOK_REDIR_DUP_OUT
A duplicate redirect output token ex: “>&”
-
enumerator TOK_LPAREN
A left parenthesis token ex: “(”
-
enumerator TOK_RPAREN
A right parenthesis token ex: “)”
-
enumerator TOK_ARITH_OPEN
A open arithmetic sequence ex: “$((”
-
enumerator TOK_ARITH_CLOSE
A close arithmetic sequence ex: “))”
-
enumerator TOK_EOF
An end-of-file token
-
enumerator TOK_ERROR
An error token (invalid syntax)
-
enumerator TOK_WORD
Functions
-
t_list *lexer_tokenize(const char *input)
Tokenize an input string into a list of tokens.
This function takes a string as input and breaks it down into individual tokens based on the shell’s syntax rules.
skip spaces and recognize the type of token before adding it in the list. The memory is allocated and the list must be freed.
- Parameters:
input – The input string to tokenize.
- Returns:
A pointer to a t_list containing the parsed tokens, or NULL on error.
-
void lexer_reset_state(void)
Reset stateful counters in lexer helpers (e.g. arithmetic depth).
Called from
lexer_tokenizeso a previous malformed input cannot leak state into the next tokenization.
-
int lexer_check_quotes(const char *input, char *unclosed_quote)
Check for unclosed quotes.
Sets *unclosed_quote to the quote char (’'’, ‘”’) or 0 if balanced.
- Parameters:
input – The input string to check.
unclosed_quote – A pointer to a char where the unclosed quote will be stored.
- Returns:
1 if an open quote is found, 0 if balanced.
-
void lexer_free_tokens(t_list *tokens)
Free an entire token list (tokens + strings + nodes).
This function frees all memory associated with a list of tokens.
- Parameters:
tokens – The list of tokens to free.
-
t_list *token_new(t_token_type type, char *value, int io_number)
Token helpers (used by lexer internally and by tests)
These functions are used to create and free tokens, check for operators, and read operators and words from the input string. They are also used by the unit tests to verify the correctness of the lexer implementation.
- Parameters:
type – The type of the token to create.
value – The raw string value of the token (with quotes preserved).
io_number – The file descriptor number for redirection tokens (set to -1 if not applicable).
- Returns:
A new t_list node containing the created token, or NULL on allocation failure.
-
int is_operator(char c)
check if the character is in “&|><;{}\n”
-
int is_operator_start(const char *line)
manage the digits in case of redirection then call is_operator
-
t_list *read_operator(const char **line)
choose the good function to tokenize
-
t_list *read_word(const char **line)
-
struct t_operator
- #include <lexer.h>
Struct representing a shell token.
This struct holds the type of the token, its raw value (with quotes preserved for later expansion), and an optional io_number for redirection tokens.
Public Members
-
const char *literal
The literal string of the operator (e.g., “|”, “&&”)
-
t_token_type type
The token type corresponding to this operator
-
const char *literal
-
struct t_token
- #include <lexer.h>
Token data node.
Stored in a t_list* returned by lexer_tokenize (each node->content is a t_token*). No *next field - traversal is via the t_list wrapper.
Public Members
-
t_token_type type
Type of the token (word, operator, etc.)
-
char *value
Raw token string (quotes preserved for expander)
-
int io_number
File descriptor number for redirection tokens (-1 if none)
-
t_token_type type
Entry Point
main file of lexer module
- Author
jguillem
Functions
-
t_list *lexer_tokenize(const char *input)
Tokenize an input string into a list of tokens.
skip spaces and recognize the type of token before adding it in the list. The memory is allocated and the list must be freed.
Word Tokens
file to manage words of the prompt command
- Author
jguillem
Operator Tokens
file to manage operators of the prompt command
- Author
jguillem
Functions
-
void lexer_reset_state(void)
Reset stateful counters in lexer helpers (e.g. arithmetic depth).
Called from
lexer_tokenizeso a previous malformed input cannot leak state into the next tokenization.
-
int is_operator(char c)
check if the character is in “&|><;{}\n”
-
int is_operator_start(const char *line)
manage the digits in case of redirection then call is_operator
-
static int extract_io_number(const char **line)
extract the file descriptor before the operator
- Parameters:
line – a pointer on the string of the operator
- Returns:
an int
-
static t_list *create_operator_token(const char **line, int io_number, const char *literal, t_token_type type)
Create a new t_list token node.
- Parameters:
line – Address of the string to tokenize
io_number – file descriptor for redirection
literal – representation of the operator
type – A t_token_type
- Returns:
A t_list token node
-
t_list *read_operator(const char **line)
choose the good function to tokenize
Variables
-
static int g_arith_depth = 0
Arithmetic nesting depth, tracked across calls to read_operator.
Incremented on
$((, decremented on)). When zero,)) must NOT match as TOK_ARITH_CLOSE because it would steal the two closing parens of plain nested subshells like(…)) and produce a spurious syntax error (regression introduced by PR #28). Reset fromlexer_tokenizevialexer_reset_stateso a malformed previous input cannot poison the next one.
- static const t_operator operators [] = {{";",TOK_SEMICOLON},{"\n",TOK_NEWLINE},{"$((",TOK_ARITH_OPEN},{"(",TOK_LPAREN},{"))",TOK_ARITH_CLOSE},{")",TOK_RPAREN},{"||",TOK_OR},{"|",TOK_PIPE},{"&&",TOK_AND},{"&",TOK_AMPERSAND},{"<<-", TOK_HEREDOC_STRIP},{"<<",TOK_HEREDOC},{"<&",TOK_REDIR_DUP_IN},{"<",TOK_REDIR_IN},{">>",TOK_REDIR_APPEND},{">&",TOK_REDIR_DUP_OUT},{">",TOK_REDIR_OUT},{NULL, 0}}
array of struct s_operator struct
match literal representation and token type
important to keep long operators before short ones (e.g. && and &)
this allow strncmp to works properly
Token Helpers
Functions
-
t_list *token_new(t_token_type type, char *value, int io_number)
Token helpers (used by lexer internally and by tests)
These functions are used to create and free tokens, check for operators, and read operators and words from the input string. They are also used by the unit tests to verify the correctness of the lexer implementation.
- Parameters:
type – The type of the token to create.
value – The raw string value of the token (with quotes preserved).
io_number – The file descriptor number for redirection tokens (set to -1 if not applicable).
- Returns:
A new t_list node containing the created token, or NULL on allocation failure.
-
void token_free(t_token *token)
-
void lexer_free_tokens(t_list *tokens)
Free an entire token list (tokens + strings + nodes).
This function frees all memory associated with a list of tokens.
- Parameters:
tokens – The list of tokens to free.